An Introduction to Serverless and FaaS (Functions as a Service)


Audio : Listen to This Blog.
Evolution of Serverless Computing
We started with building monolithic applications for installing and configuring OS. This was followed by installing application code on every PC to VM’s to meet their user’s demand. It simplified the deployment and management of the servers. Datacenter providers started supporting a virtual machine, but this still required a lot of configuration and setup before being able to deploy the application code.
After a few years, Containers came to the rescue
Dockers made its mark in the era of Containers, which made the deploying of applications easier. They provided a simpler interface to shipping code directly into production. They also made it possible for platform providers to get creative. Platforms could improve the scalability of users’ applications. But what if developers could focus on even less? It can be possible with Serverless Computing.
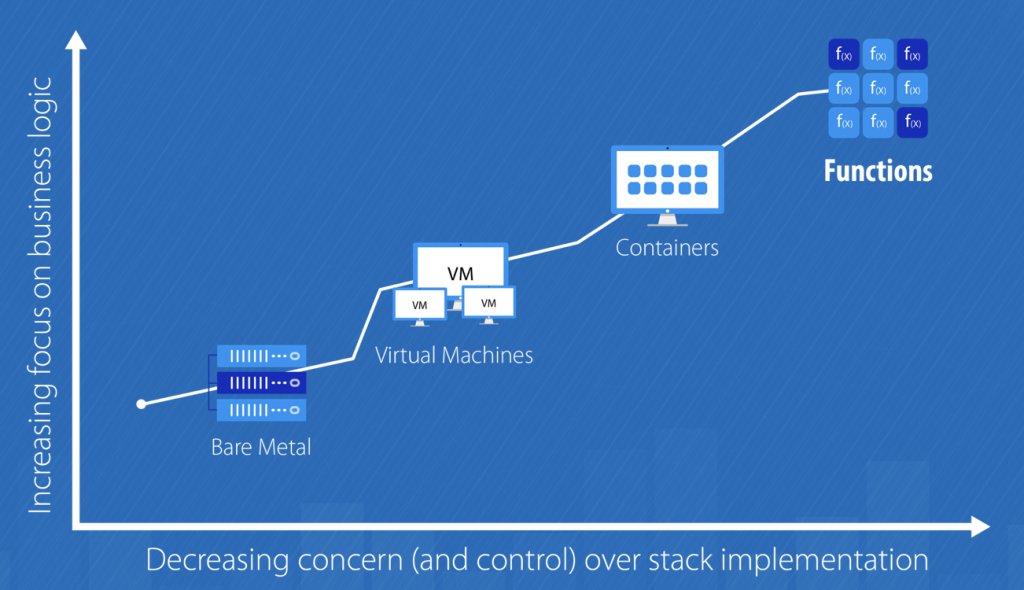
What exactly is “Serverless”?
Serverless computing is a cloud computing model which aims to abstract server management and low-level infrastructure decisions away from developers. In this model, the allocation of resources is managed by the cloud provider instead of the application architect, which brings some serious benefits. In other words, serverless aims to do exactly what it sounds like—allow applications to be developed without concerns for implementing, tweaking, or scaling a server.
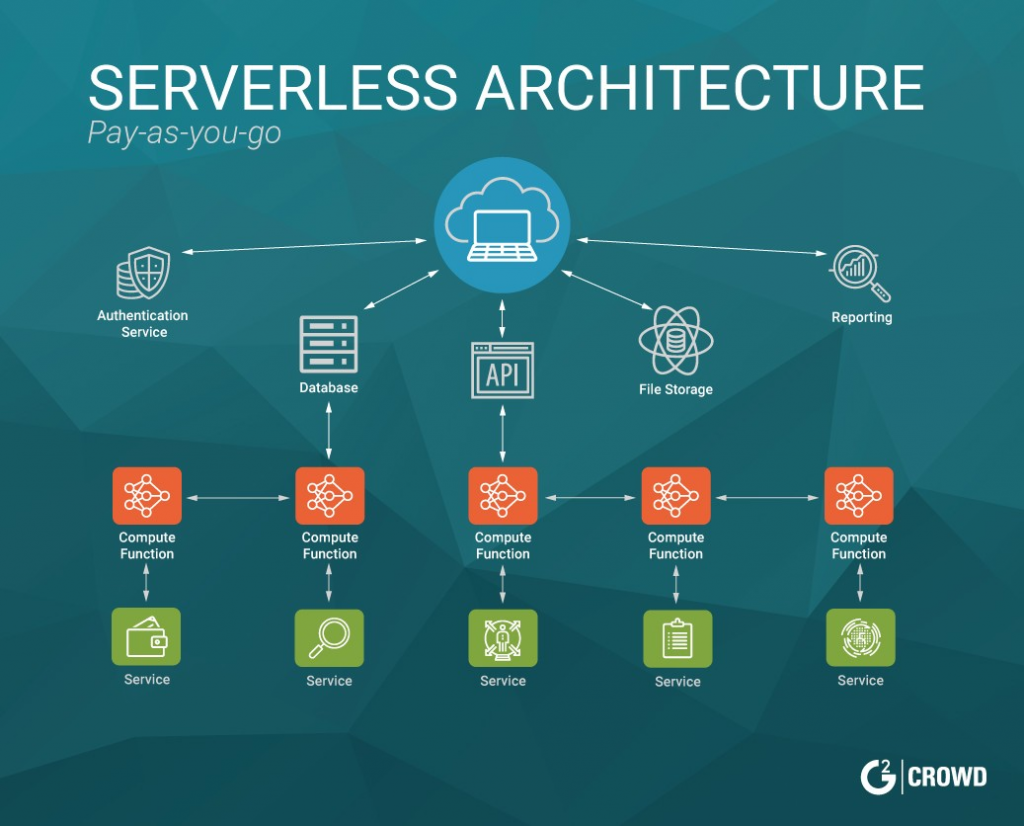
In the below diagram, you can understand that you wrap your Business Logic inside functions. In response to the events, these functions execute on the cloud. All the heavy lifting like Authentication, DB, File storage, Reporting, Scaling will be handled by your Serverless Platform. For Example AWS Lamba, Apache IBM openWhisk.
When we say “Serverless Computing,” does it mean no servers involved?
The answer is No. Let’s switch our mindset completely. Think about using only functions — no more managing servers. You (Developer) only care about the business logic and leave the rest to the Ops to handle.
Functions as a Service (FaaS)
It is an amazing concept based on Serverless Computing. It provides means to achieve the Serverless dream allowing developers to execute code in response to events without building out or maintaining a complex infrastructure. What this means is that you can simply upload modular chunks of functionality into the cloud that are executed independently. Sounds simple, right? Well, it is.
If you’ve ever written a REST API, you’ll feel right at home. All the services and endpoints you would usually keep in one place are now sliced up into a bunch of tiny snippets, Microservices. The goal is to completely abstract away servers from the developer and only bill based on the number of times the functions have been invoked.
Key components of FaaS:
- Function: Independent unit of the deployment. E.g.: file processing, performing a scheduled task
- Events: Anything that triggers the execution of the function is regarded as an event. E.g.: message publishing, file upload
- Resources: Refers to the infrastructure or the components used by the function. E.g.: database services, file system services
Qualities of a FaaS / Functions as a Service
- Execute logic in response to events. In this context, all logic (including multiple functions or methods) are grouped into a deployable unit, known as a “Function.”
- Handle packaging, deployment, scaling transparently
- Scale your functions automatically and independently with usage
- More time focused on writing code/app specific logic—higher developer velocity.
- Built-in availability and fault tolerance
- Pay only for used resources
Use cases for FaaS
- Web/Mobile Applications
- Multimedia processing: The implementation of functions that execute a transformational process in response to a file upload
- Database changes or change data capture: Auditing or ensuring changes meet quality standards
- IoT sensor input messages: The ability to respond to messages and scale in response
- Stream processing at scale: Processing data within a potentially infinite stream of messages
- Chatbots: Scaling automatically for peak demands
- Batch jobs scheduled tasks: Jobs that require intense parallel computation, IO or network access
Some of the platforms for Serverless
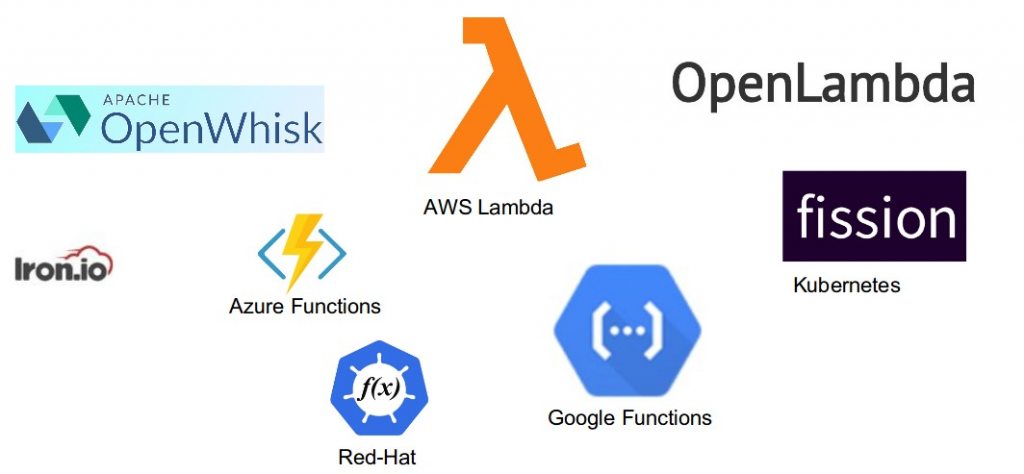
Introduction to AWS Lambda (Event-driven, Serverless computing platform)
Introduced in November 2014, Amazon provides it as part of Amazon Web Services. It is a computing service that runs code in response to events and automatically manages the computing resources required by that code. Some of the features are:
- Runs Stateless – request-driven code called Lambda functions in Java, NodeJS & Python
- Triggered by events (state transitions) in other AWS services
- Pay only for the requests served and the compute time
- Allows to Focus on business logic, not infrastructure
- Handles your codes: Capacity, Scaling, Monitoring and Logging, Fault Tolerance, and Security Patching
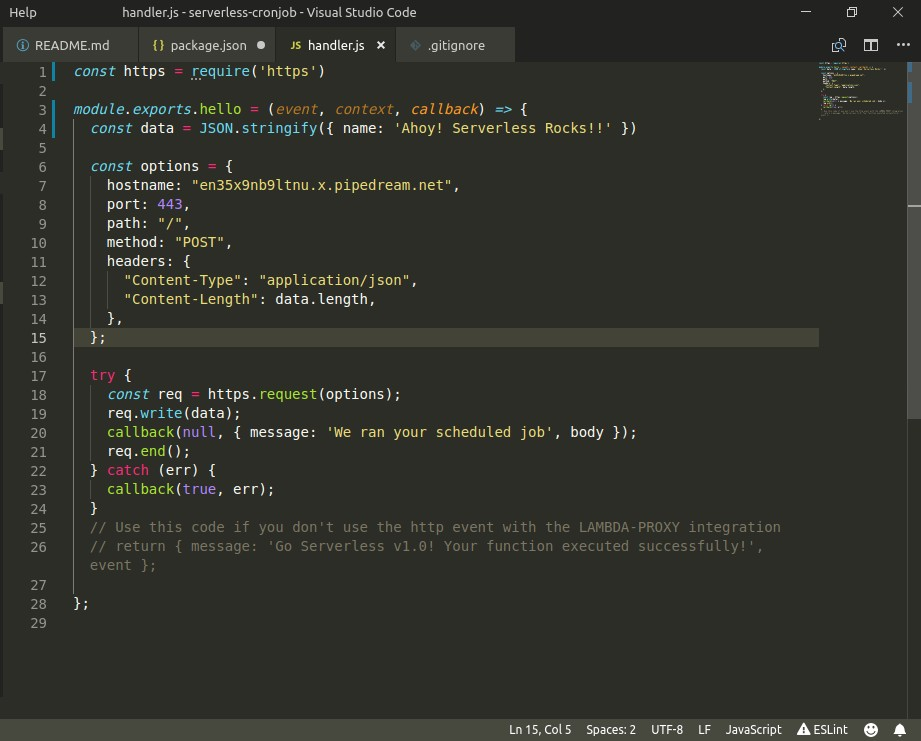
Sample code on writing your first lambda function:
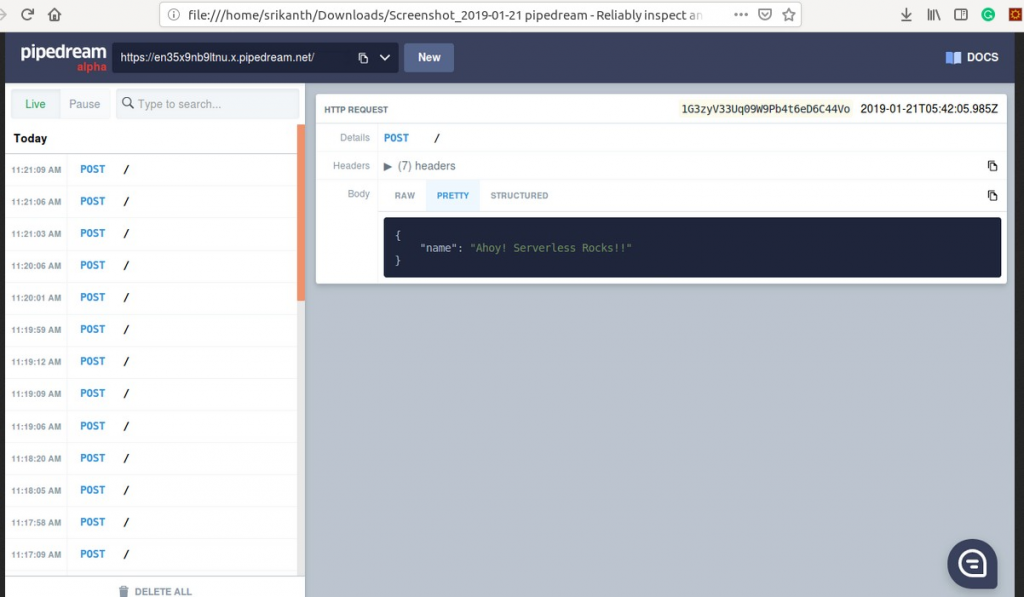
This code demonstrates simple-cron-job written in NodeJS which makes HTTP POST Request for every 1 minute to some external service.
For detail tutorial, you can read on https://parall.ax/blog/view/3202/tutorial- serverless-scheduled-tasks
Output: Makes a POST call for every minute. The function that is firing POST request is actually running on AWS Lambda (Serverless Platform).
Conclusion:
In conclusion, serverless platforms today are useful for tasks requiring high-throughput rather than very low latency. It also helps to complete individual requests in a relatively short time window. But the road to serverless can get challenging depending on the use case. And like any new technology innovations, serverless architectures will continue to evolve to become a well-established standard.
References:
https://blog.cloudability.com/serverless-computing-101/
https://www.doc.ic.ac.uk/~rbc/papers/fse-serverless-17.pdf
https://blog.g2crowd.com/blog/trends/digital-platforms/2018-dp/serverless-computing/
https://www.manning.com/books/serverless-applications-with-node-js