Replication Strategies for Enhanced Data Protection and Recovery


Audio : Listen to This Blog.
Why replication?
Murphy’s law states that “Anything that can go wrong will go wrong.”
This holds true for storage environments as well. Disaster can strike anytime. It can be either man-made like power failures and outages in various parts of a storage system (like networks, databases, processors, disks etc.) or software bugs and other human errors. In addition to that, natural disasters like floods, earthquakes etc. may hit a data-center.
During a disaster, we should consider two key factors:
- Data loss (measured by RPO)
- Time to restore the available data (measured by RTO)
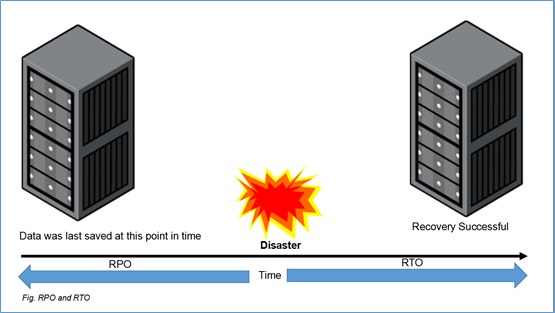
During the 1980s and early 1990s, companies would mostly protect their data using backups. However, increase in the demand made the data inadequate
Backup involves making copies of data and storing them off-site (usually in magnetic tapes,hard-drives etc.). During any disaster, the off-site backup copy is taken. Using this copy, storage engineers restore the system. This takes a lot of time resulting in high RPO as well as high RTO. Despite taking frequent backups, the time to recover a system from a disaster is considerably high, since data has to be transferred to the server location.
With every second, the business worlds of today are expanding and there are huge amounts of data that needs to be protected. It is no longer just enough to protect data. It is important to ensure that critical processes are restored and data is available as early as possible.
The shortcomings with backup gave rise to the development of replication technologies.
What is replication?
In replication, data is copied from one storage system to another (usually in the form of snapshots). This data lives in its original form in the secondary storage system. During any disaster, the secondary storage system can immediately be used. Since the data is already in usable form, there is no need to perform any further operations on the data or to copy the data to some other location. This results in much less downtime. Overall, the RTO and RPO is much less.
Types of replication
Some of the major types of replication include:
- Asynchronous replication
- Synchronous replication
- Near-synchronous or semi-synchronous or partially-synchronous replication
All these types of replication can be paused and resumed when required.
1.Asynchronous replication
As the name suggests, data is not written to the secondary storage system simultaneously. Rather, snapshots taken in the primary storage system are copied to the secondary storage system at certain intervals. Most of the storage companies provide intuitive UI where user can configure and edit the schedules. Most storage companies support schedules like Hourly, Daily, Weekly, Monthly, quarterly, custom etc.
Moreover, some storage companies also provide users with an option to perform replication to cloud.
Pros:
Provides excellent performance
Cons:
More chance of data loss. RPO depends on the protection schedule
2.Synchronous replication
In synchronous replication, whenever any data-commit takes place in primary storage, a commit is also made in secondary storage. A commit is considered successful when the primary receives an acknowledgement from secondary indicating successful commit. This ensures that there is always a read-to-use mirror available when any disaster happens.
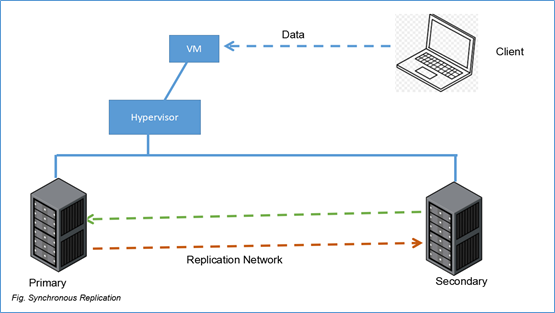 Fig. Synchronous Replication
Fig. Synchronous Replication
List of steps that take place for a successful write operation:
- Client writes data to VM.
- Data goes to the Primary storage system, through the hypervisor
- Same data goes to the Secondary storage system, through the replication network.
- Data is successfully “written” in secondary
- Secondary sends an acknowledgement to Primary
- Primary sends the acknowledgement to the VM
Pros:
Guarantees “zero data loss.”
Cons:
Performance decreases considerably since primary storage has to wait for an acknowledgement from secondary, during every write operation. This latency is proportional to the distance between the primary and secondary storage locations.
Manual Failover
When any disaster happens, Users can perform a manual failover through the UI, with a single mouse click. The secondary storage then acts as primary, so there is almost 0 downtime.
Automatic Failover
This is an advanced feature. A monitoring system is connected to both primary and secondary storage systems. It checks for the health of both the systems at regular intervals. When any of the system goes down, automatically the other system is made as primary.
Some of the storage companies that provide Synchronous replication capability include Tintri by DDN,Pure Storage, Nutanix, HPE Nimble and EMC Dell.
3.Near-synchronous or semi-synchronous or partially- synchronous replication
This type of replication is same as synchronous replication. However, here the primary storage does not have to wait for an acknowledgement from secondary.
Pros:
Provides better performance than synchronous replication
Cons:
More chances of data loss compared to synchronous replication.
Conclusion
| Asynchronous Replication | Near Synchronous Replication | Synchronous Replication | |
| Protection Schedule | Needs to be configured | NOT needed | NOT needed |
| Latency | Low | Low | High |
| RPO | Minimum is 15 minutes depending on the protection schedule | Provides 0 RPO | |
| Expenses | Least expensive | Moderately expensive | Most expensive |
| Distance between data-centers | Works well even when distance between primary and remote data-center increases | Works well even when distance between primary and remote data-center increases | Latency is proportional to the distance between primary and remote data-centers |
| RTO | Short RTO but not as good as synchronous replication | Short RTO but not as good as synchronous replication | Provides close to 0 RTO |
| Infrastructure | Can work well with medium bandwidth network | Can work well with medium bandwidth network | Requires bandwidth network |
As the above table shows, each replication technology is different in terms of cost, latency, data availability etc. It is necessary to categorize the different types of workloads in the data-center environment and then apply the appropriate type of replication technology.
References
https://searchdisasterrecovery.techtarget.com/definition/synchronous-replication
1 Comment
Want to learn more about it.