So You Want to Build Your Own Data Center?


Audio : Listen to This Blog.
In today’s internet-of-things world, companies run their applications 24×7, and this generally results in a lot of users or data. This data needs to be stored, analyzed, and post-processed; in essence, some action needs to be taken on it. We are looking at huge fluctuating workloads. The scale of operations is enormous, and to handle this kind of mammoth operations, clusters are built. In the age of commodity hardware, clusters are easy to build, but clusters with specific software stack that could do only one type of task (static partitioning of resources) lead to less optimal resource utilization, because it is possible that no task of that type is running at a given time.
For example, Jenkins slaves in a CI cluster could be sitting idle at night or during a common vacation time when developers are not pushing code. But let’s say, when product release time is near, it might so happen that developers are pushing and hacking away at code so frequently that the build queue becomes longer due to the need for slaves to run the CI jobs. Both the situations are undesirable and reduce the efficiency and ROI of the company.
Dynamic partitioning of resources is the solution to fix the above issue. Here, you pool your resources (CPU, memory, IO, etc.) such that nodes from your cluster act as one huge computer. Based on your current requirement, resources are allocated to the task that needs it. So the same pool of hardware runs your Hadoop, MySQL, Jenkins, and Storm jobs. You can call this “node abstraction.” Thus achieve diverse cluster computing on commodity hardware by fine-grained resource sharing. To put it simply, different distributed applications run on the same cluster.
Google has mastered this kind of cluster computing for almost 2 decades now. The outside world does not know much about their project known as Borg or its successor, Omega. Ben Hindman, an American entrepreneur, and a group of researchers from UC Berkeley came up with an open-source solution inspired by Borg and Omega.
Enter Mesos!
What Is Mesos?
Mesos is a scalable and distributed resource manager designed to manage resources for data centers.
Mesos can be thought of as “distributed kernel” that achieves resource sharing via APIs in various languages (C++, Python, Go, etc.) Mesos relies on cgroups to do process isolation on top of distributed file systems (e.g., HDFS). Using Mesos you can create and run clusters running heterogeneous tasks. Let us see what it is all about and some fundamentals on getting Mesos up and running.
Basic Terminology and Architecture
Mesos follows the master-slave architecture. It can also have multiple masters and slaves. Multi-master architecture makes Mesos fault-tolerant. The leader is elected through ZooKeeper.
A Mesos application, or in Mesos parlance a “framework,” is a combination of a scheduler and an executor. Framework’s scheduler is responsible for registering with the Mesos master and also for accepting or rejecting resource offers from the Mesos master. An executor is a process running on Mesos slave that actually runs the task. Mesos has a distributed two-way scheduling called resource offer. A “resource offer” can be thought of as a two-step process, where initially a message from the Mesos master is sent to a particular framework on a Mesos slave about what resources (CPU, memory, IO etc) are available to it. The framework decides which offers it should accept or reject and which tasks to run on them.
A task could be a Jenkins job inside a Jenkins slave, a Hadoop MapReduce job, or even a long-running service like a Rails application. Tasks run in isolated environment which can be achieved via cgroups, Linux containers, or even Zones on Solaris. Since Mesos v0.20.0, native Docker support has been added as well.
Examples of useful existing frameworks include Storm, Spark, Hadoop, Jenkins, etc. Custom frameworks can be written on the API provided by Mesos kernel in various languages–C++, Python, Java, etc.
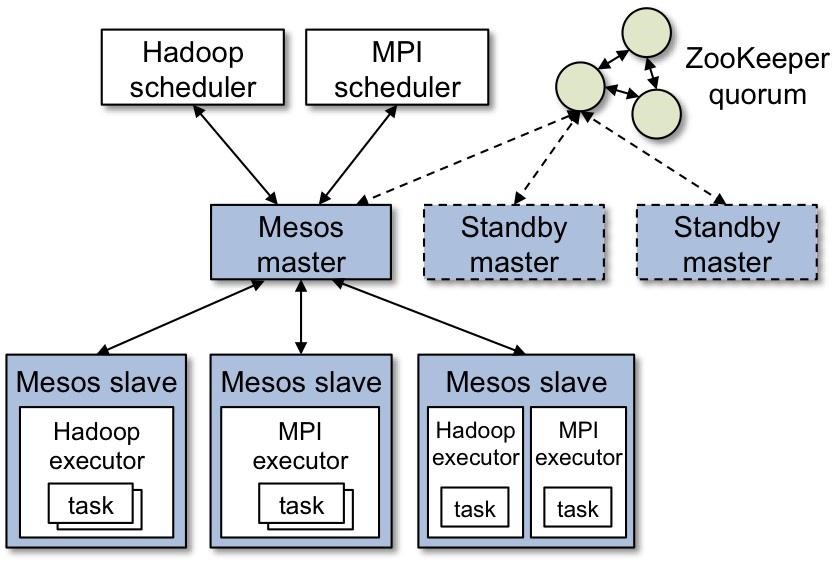
Image credit: Mesos documentation
A Mesos slave informs Mesos master about its available resources that the slave is ready to share. The Mesos master based on allocation policy makes “resource offers” to a framework. The framework’s scheduler decides whether or not to accept the offers. Once accepted, the framework sends a task description (and its resource requirements) to the Mesos master it needs to run. The Mesos master then sends these tasks to the Mesos slave to be executed on the slave by the framework’s executor. Finally the framework’s executor launches the task. Once the task is complete and the Mesos slave is idle, it reports back to the Mesos master about the freed resources.
Mesos is being used by Twitter for many of their services including analytics, typeahead, etc. Many other companies who have large cluster and big data requirements like Airbnb, Atlassian, Ebay, Netflix, and others use Mesos.
What Do You Get With Mesos?
Arguably the most important feature that you can get out of Mesos would be “resource isolation.” This resource can be CPU, memory, etc. Mesos allows running multiple distributed applications on the same cluster, and this gives us increased utilization, efficiency, reduced latency, and better ROI.
How to Build and Run Mesos on Your Local Machine?
Enough with the theory! Now let us do fun bits of actually building the latest Mesos from Git and running Mesos and test frameworks. The below steps assume you are running Ubuntu 14.04 LTS.
* Get Mesos
git clone https://git-wip-us.apache.org/repos/asf/mesos.git
* Install dependencies
sudo apt-get update
sudo apt-get install build-essential openjdk-6-jdk python-dev python-boto libcurl4-nss-dev libsasl2-dev maven libapr1-dev libsvn-dev autoconf libtool
* Build Mesos
cd mesos
./bootstrap
mkdir build && cd build
../configure
make
* Run tests
make check
* Install Mesos
make install
* Prepare the system
sudo mkdir /var/lib/mesos
sudo chown /var/lib/mesos
* Run Mesos Master
./bin/mesos-master.sh --ip=127.0.0.1 --work_dir=/var/lib/mesos
* Run Mesos Slave
./bin/mesos-slave.sh --master=127.0.0.1:5050
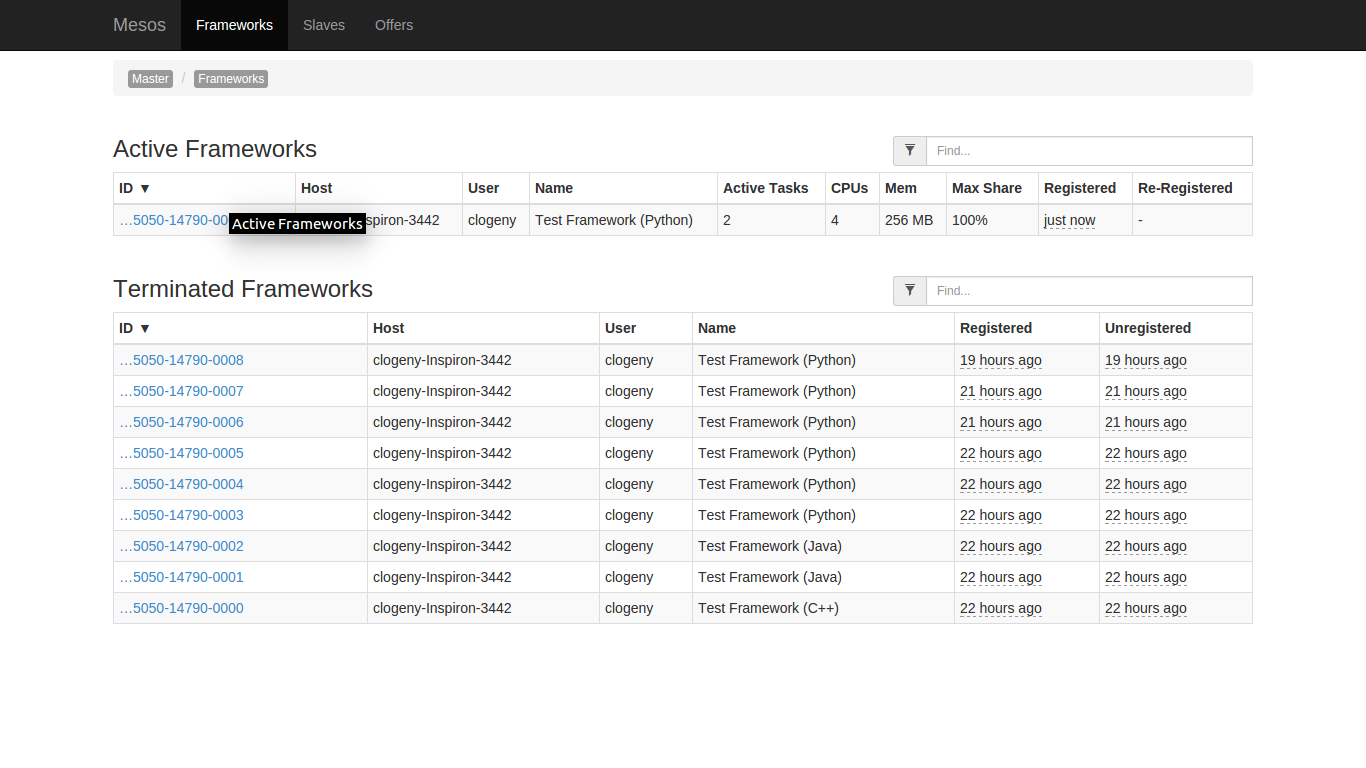
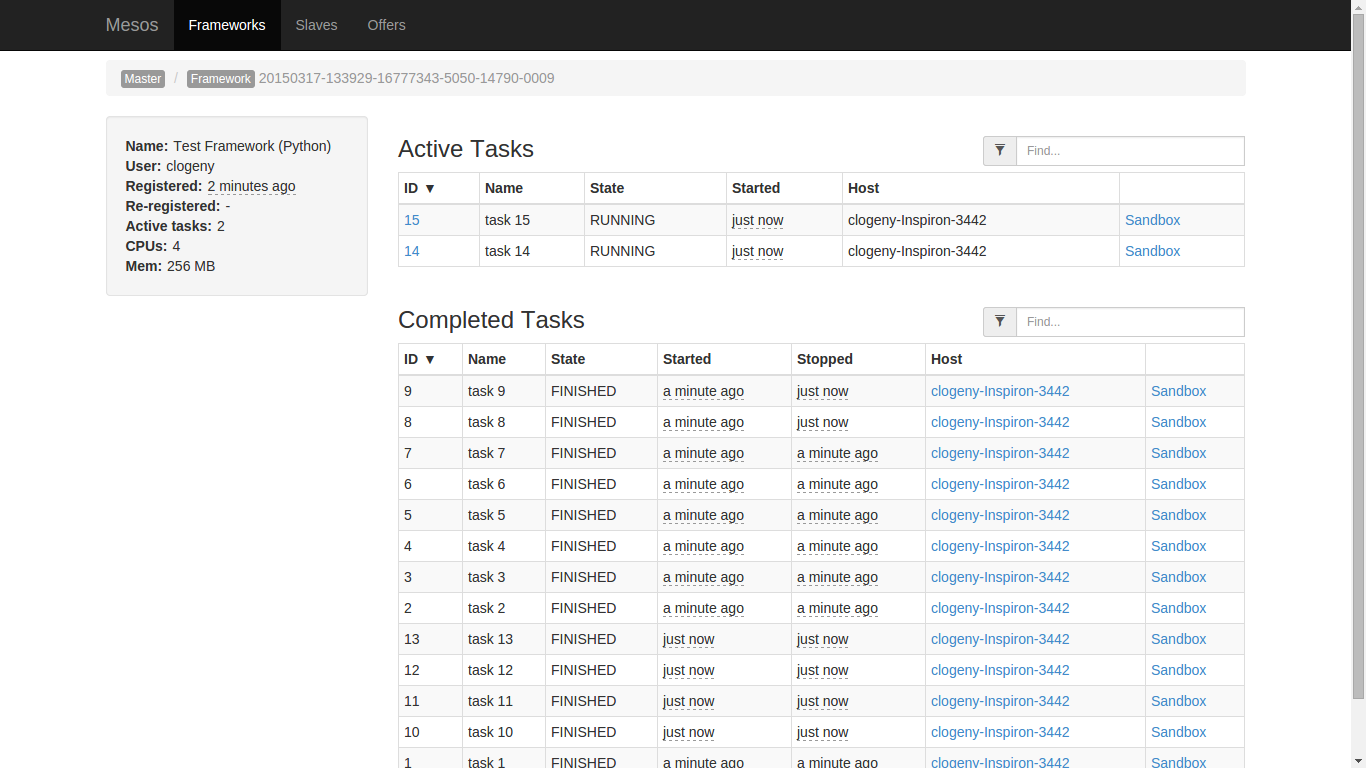
Mesos by itself is incomplete. It uses frameworks to run distributed applications. Let’s run a sample framework. Mesos comes with a bunch of example frameworks located in “mesos/src/examples” folder of your mesos Git clone. For this article, I will run the Python framework that you should find in “mesos/src/examples/python”.
You can play with the example code for more fun and profit. See what happens when you increase the value of TOTAL_TASKS in “mesos/src/examples/python/test_framework.py”. Or you could try to simulate different duration taken by tasks to execute by inserting a random amount of sleep in run_task() method inside “mesos/src/examples/python/test_executor.py”.
* Run frameworks
cd mesos/build
./src/examples/python/test-framework 127.0.0.1:5050
Conclusion
Marathon, a meta-framework on top of Mesos, is distributed init.d. It takes care of starting, stopping, restarting services, etc. Chronos, a scheduler, think of it as distributed and fault-tolerant cron (*nix scheduler), which takes care of scheduling tasks. Mesos even has a CLI tool (pip install mesos.cli), using which you can interact (tail, cat, find, ls, ps, etc.) with your Mesos cluster via command line and feel geeky about it. A lot can be achieved with Mesos, Marathon, and Chronos together. But more about these in a later post. I hope you have enjoyed reading about Mesos. Please share your questions through the comments.